整数のなかみ(後編)
前回の続きです。
前回は、2の補数まで解説しました。今回は、さらに整数についてさらに具体的に見ていこうと思います。
|
|
符号の差
さて、話を元に戻して、int型、つまり「符号あり整数値」について見てみましょう。
このint型についても、UINTと同じように変数の中身を見てみましょう。
|
int iTest1 = -1;
TRACE( "%d, %u, %X\n", iTest1, iTest1, iTest1 );
// -1, 4294967295, FFFFFFFF
UINTと比べてどうですか? そう、 まったく同じです。
この辺で「−1と4294967295が一致しちゃう理由」が分かると思います。特に指定されていないこういった「素の定数」は intと解釈されます。両方ともFFFFFFFFなので、一致してしまうというわけです。この理由から、−1と255は一致しません。255は000000FFになるため、−1とは一致しないのです。
ちなみにこういった問題から、定数値の最後に「L」(アルファベットの「エル」です。小文字でもいいんですが、1と似てるんで使わない方がいいでしょう)を付けると「32ビット整数」とはっきりと示すことになります。また、「U」(「ユー」です)を付けると「符号ナシ」ということを示します。
よくSendMessage()のWPARAMとかに渡す引数で「0L」と書かれているのは、「00000000」という値を渡すということをはっきりと示しているわけです。
話を戻しましょう。以上のようにintとUINTは中のビットデータは同じなのです。では何が違うのでしょうか。
ま、とりあえず以下の結果を見てみてください(自分でも試してみてね)。
|
UINT uiTest1 = -1; //「符号ナシ」にマイナス……
TRACE( "%d, %u, %X\n", uiTest1, uiTest1, uiTest1 );
// -1, 4294967295, FFFFFFFF
uiTest1 = 1;
uiTest1 = uiTest1 - 2; //マイナスになっちゃうって……
TRACE( "%d, %u, %X\n", uiTest1, uiTest1, uiTest1 );
// -1, 4294967295, FFFFFFFF
int iTest1 = 4294967295; //入りきらないんじゃ……
TRACE( "%d, %u, %X\n", iTest1, iTest1, iTest1 );
// -1, 4294967295, FFFFFFFF
if( iTest1 == 4294967295 ) //ま、これは当然だけど……
TRACE( "Hit(4294967295)\n" );
// Hit!!
if( iTest1 == -1 ) //こっちも……?
TRACE( "Hit(-1)\n" );
// Hit!!
++iTest1; //ループしちゃうわけね……
TRACE( "%d, %u, %X\n", iTest1, iTest1, iTest1 );
// 0, 0, 0
iTest1 = -1;
uiTest1 = iTest1; //型きゃストの必要はなし。
TRACE( "%d, %u, %X\n", uiTest1, uiTest1, uiTest1 );
// -1, 4294967295, FFFFFFFF
uiTest1 = -1;
iTest1 = uiTest1; //型きゃストの必要はなし。
TRACE( "%d, %u, %X\n", uiTest1, uiTest1, uiTest1 );
// -1, 4294967295, FFFFFFFF
|
とゆーふーに、はっきり言ってintもUINTもほとんど違いはありません。でも、まったく同じってわけでもないんです。
|
int iTest1 = 0;
int iTest2 = -1; //とうぜんiTest2 < iTest1ですね
if( iTest1 < iTest2 )
TRACE( "int: %X < %X\n", iTest1, iTest2 );
else
TRACE( "int: %X < %X\n", iTest2, iTest1 );
// int: FFFFFFFF < 0
UINT uiTest1 = 0;
UINT uiTest2 = -1; //=4294967295だから……
if( uiTest1 < uiTest2 )
TRACE( "UINT: %X < %X\n", uiTest1, uiTest2 );
else
TRACE( "UINT: %X < %X\n", uiTest2, uiTest1 );
// UINT: 0 < FFFFFFFF
if( uiTest1 < iTest2 ) //コンパイルワーニング。
TRACE( "UINT: %X < %X\n", uiTest1, uiTest2 );
|
このように、大小判断では、符号のあるナシがちゃんと働く仕組みになっています。また、デフォルトの設定なら、intとUINTを比較すると警告が出ます。
実際には、符号のあるナシに意味があるのは、このくらいです。
|
変数の中身
今まで見てきて分かったとおり、 intも UINTも 単なるビットの並びでしかありません。中のデータがプラスで表示されるかマイナスで表示されるかということは、その「表示する方法」によって変わるのです。
「intは整数値を扱える」という風に憶えてしまうと、まるで「int型の変数には整数値がそのまま入っている」と錯覚してしまうでしょう。
でも実際には違うのです。変数に入っているのはビットの並びだけです。0と1が32個並んでいるだけです。それを1とか30000とか−50とか、そういった整数値としてとらえるのは関数の役目です。コンピューター内部には、数字なんて世界は存在しないんです。
こういうことを意識しなければならないのは、おそらくC/C++のみだと思います。そして、C/C++を使う以上、この事は常に注意していなければなりません。この仕組みを使う場面は何度となく出てくるからです。
|
整数型の仲間
と、その「場面」について説明する前に、 intと UINTの他にも整数型がたくさんあるので、それらについても見ていきましょう。
 まずは1バイトの整数から。これにはcharとBYTEがあります。
まずは1バイトの整数から。これにはcharとBYTEがあります。
charは文字列に使う変数で、signedとunsignedのふたつがあります。BYTEはunsignedのみです。
2バイトの整数は、shortとWORD。
同様にshortは両方の符号があります。またWORDはunsignedのみで、これから出てくるDWORD等の関係でよく使います。
4バイトの整数はたくさんあります。まずlongとLONG。LONGはsigned longと同じで、ウィンドウズではよく使われる型です。
まだあります。DWORDはunsigned longと同じです。これ自体はあまり使いませんが、これと同じ型のWPARAMとLPARAMはよく見かけるでしょう。これは、メッセージの受け渡しに使うパラメーターです。
あと、実はintとUINTは、4バイトと決まっているわけではありません。intは、「もっとも標準的なサイズの整数」と定義されていて、コンピューターやOSによって違います。
ウィンドウズ95やNT4.0は32ビットなので、intも32ビット、つまり4バイトになりますが、ウィンドウズ3.1は16ビットなので、intも16ビット、つまり2バイトになります。
でも、Win32SDKを用いてプログラミングをしているのなら、4バイトと決めつけて大丈夫でしょう(もちろん、将来のウィンドウズは64ビットになるでしょうけど……)。
以上をふまえて、WPARAMとLPARAMについて見てみましょう。
|
HIWORDとLOWORD

MFCを使っているときはあまり気になりませんが、メッセージを受け取るときには各パラメーターが WPARAMと LPARAMに入っていて、これを型キャストして他の値に変換し、使用するという形を取ります。MFCは自動的にこの変換を行ってくれています。が、ときどき使用する場合もあるでしょう。
そういうとき、Win32SDKリファレンスにしばしば Value of the high-order word of wParamとか Value of the low-order word of wParamとか書かれていることがあると思います。これは、 WPARAM等をふたつに切って、 上と下に分けた話です。
WPARAM等の32ビット整数値は、当然32個ビットの並びがあるということです。ビットだと多すぎるのでバイトにすると、4バイトの並びがあるということになります。この4バイトを真ん中で区切り、上2バイトをHIWORD、下2バイトをLOWORDととらえることで、ひとつの4バイト変数にふたつの2バイト変数が入っていると考える事ができます(2バイト変数ならなんでもいいんですが、とりあえずWORDが標準だったとゆーことで)。
こうすることで、ふたつしかないパラメーターに最大4つまでの値を入れることに成功しているというわけです(でもあんま良くないと思うから、自分のプログラムには使わないよーに。「良い子はまねしないでね」ってやつです)。この値はHIWORD()とLOWORD()というマクロで簡単に取得できるようになっていますので、それほど神経質になることはないでしょう。
もしかしたら、受け取る側ではなく送る側でよく使うかもしれません。そういう場合には、ふたつのWORDからひとつのWPARAMを作り出さなければなりません。
そのためのマクロもちゃんと用意されていて、MAKELPARAM()の第1引数にLOWORDを、第2引数にHIWORDを渡すことで、戻り値にくっついたあとのLPARAMが返ってきます(MAKEWPARAMというマクロもあります)。
とにかくこのマクロは引数の順番を間違えないことが重要。すごく混乱しますので常に注意してください。
|
ビットフラグ
同じように、「変数はビットの並び」ということを知っていないと分かりにくいものに、 ビットフラグがあります。
CWnd::Create()から行ける 「ウィンドウスタイル」のページに、ウィンドウのタイプを決めるフラグの一覧があります。このフラグはWin32APIの CreateWindow()でも使用するもので、ウィンドウズでもっとも標準的なフラグと言えるでしょう。
あ、「フラグ」というのは「旗」のことで、「何かを示すもの」という意味です。サッカーでオフサイドになったら旗が上がりますよね。あれと同じです(もしかしてゲーム用語かも……)。
 話が逸れました。で、このフラグはWinuser.hの中で、整数値として定義されています。
話が逸れました。で、このフラグはWinuser.hの中で、整数値として定義されています。
ところがこれをよく見ると、
WS_POPUP : 0x80000000L、WS_CHILD : 0x40000000L、WS_MINIMIZE : 0x20000000L、WS_VISIBLE : 0x10000000Lと、なぜか1、2、4、8という数字が続きます。
これは、この16進の値を使うとそれぞれのフラグがたったひとつのビットのみ1にするために、こういった数字が並んでいるのです。このフラグを足すと、それぞれのビットは互いに干渉することなく、独立してフラグを立てることができます。そして、足したあとのビット並びを1ビットずつ調べることで、どのフラグが立っているのか分かるというわけです。欠点は、フラグを32個しか作れないということでしょうか。
さて、ではこのフラグをどうやってくっつけ、そして調べるのでしょうか。
|
ビット演算
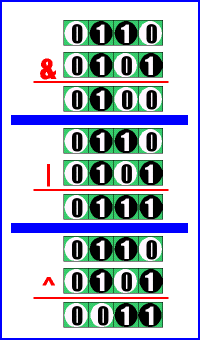
C/C++にはビット演算を行う演算子がみっつ用意されています。それは &、 |、そして ^です。
この演算子は+や−と同じように使用し(例えば i1 & i2のように)、左右の変数の同じ桁のビットを次のように変換します。
&はANDと呼び、「両方とも1の時のみ1、それ以外は0」という計算をします。例えば「0x6 & 0x5 = 0x4」となります。この演算結果から「積」とも呼ばれます。
|はORと呼び、「どっちかが1の時に1、両方とも0の時のみ0」という計算をします。例えば「0x6 | 0x5 = 0x7」となります。この演算結果から「和」とも呼ばれます。
^はEXORと呼び、「0と1の組み合わせの時に1、両方とも同じ時には0」という計算を行います。例えば「0x6 | 0x5 = 0x3」となります。これは同時に「|(OR)に似ているが両方とも1の時は0」という関係から「排他的OR」と呼ばれます。
これらの演算子を使用して、ビットフラグを操作します。例えば、ウィンドウスタイルを重ね合わせてひとつの整数値にするときには、次のように|を使用します。
|
::CreateWindow( "KABWndCls", "ほげほげ"
, WS_BORDER | WS_CAPTION | WS_MAXIMIZEBOX | WS_MINIMIZEBOX
| WS_SYSMENU | WS_VISIBLE
, 0, //以下略。
|
こうすることで、各フラグが持つビットのみが1になり、残りのビットは0の入った整数値が渡されます。
また、特定のフラグが立っているかどうかチェックするには、次のようにします。
|
BYTE bt1, bt2, bt3;
bt1 = 0x05; //0101
bt2 = 0x01; //0001
bt3 = 0x08; //1000
if( bt1 & bt2 )
TRACE( "Hit!!\n" );
else
TRACE( "not...\n" );
// Hit!!
// 0101 &
// 0001 =
// 0001
if( bt1 & bt3 )
TRACE( "Hit!!\n" );
else
TRACE( "not...\n" );
// not...
// 0101 &
// 1000 =
// 0000
|
このように、調べる整数値とフラグとを&で調べ、あれば0以外、なければ0が返ってくるので、これをifで調べればいいというわけです。
さて、最後に「特定のフラグを取り除く方法」を見てみましょう。
|
// 上のコードの続きです。
TRACE( "( 0x5 & 0x1 ) ^ 0x5 = 0x%X\n", ( bt1 & bt2 ) ^ bt1 );
// ( 0x5 & 0x1 ) ^ 0x5 = 0x4
// 0101 &
// 0001 =
// 0001 ^
// 0101 =
// 0100
TRACE( "( 0x5 & 0x8 ) ^ 0x5 = 0x%X\n", ( bt1 & bt3 ) ^ bt1 );
// ( 0x5 & 0x8 ) ^ 0x5 = 0x5
// 0101 &
// 1000 =
// 0000 ^
// 0101 =
// 0101
|
基本的には^を使うだけでフラグは取り除けます。ところが、取り除こうとしたフラグがない場合には、逆に追加してしまいます。
そこで、まず&を計算します。フラグがあるのならそのフラグが、ないのなら0が返ります。この結果を^で調べる整数値に当てると、前者なら取り除かれ、後者の場合には何も変わらないという結果になります。この2重チェックを行うことで、確実にフラグを取り除くことができます。
|
|
まとめ
以上、長々とお付き合いいただき、ありがとうございました。
今回の話はなんだかとりとめがない上に、かなりの量になってしまいました。それをカバーする意味で、できるだけ図を入れてみました。元々この講座は初心者向けのもので、できるだけしっかりと理解してもらいたいなと思い、長々と書いてしまったというわけです。
で、これまでの話をふまえて、次回は参照、そしてそのあとはポインタについてじっくりと見ていきたいと思います。「初心者キラー」と呼ばれるポインタを、とことん突き詰めてしまいましょう。
|